Información: CREDIBILIDAD Y VALIDEZ DE LA INFORMACIÓN: SOBRECARGA Y SUBCARGA DE INFORMACIÓN
DAVID MOURSUND
PROFESOR EMÉRITO, UNIVERSIDAD DE OREGON
“¿Cuál es la utilidad de tener un sinnúmero de libros y bibliotecas cuyos títulos difícilmente pueden ser leídos por sus propietarios a lo largo de toda su vida?” (Lucius Annaeus Seneca; filósofo estoico romano, estadista, dramaturgo; 4 BC-65 AD.)
Se sugiere que los futuros estudiantes necesitarán ser mucho más responsables en la determinación de la credibilidad y validez de la información que utilizarán.
Primero unas definiciones:
La Credibilidad se enfoca en la certidumbre de que la persona que justifica un hecho es creíble y confiable. Es común referirse a esta persona, a lo que escribe y a lo que habla tomándolo como verdadero y aceptable.
La Validez es un componente importante de la investigación educativa. La palabra se usa en dos situaciones diferentes:
1. Validez es la cualidad de ser o tener lógica. La validez es la extensión en la que un concepto, conclusión o medida es fundamentado.
2. Un instrumento de investigación o examen es válido si es efectivo en sus evaluaciones.
En resumen, uno puede pensar en que la credibilidad tiene una base subjetiva mientras que la validez tiene una base objetiva.
En este artículo se va a analizar la sobrecarga y subcarga de la información (Moursund, 2014). La cita mencionada al inicio del artículo confirma que el concepto de sobrecarga informativa tiene unos cuantos miles de años. Una búsqueda en Google acerca de “information overload underload” (sobrecarga y subcarga de información), produjo más de cincuenta y cuatro mil resultados.
El Ejemplo de la Cámara Digital
Tengo una cámara relativamente barata de 16-megapixeles. Tomo una fotografía con ella y obtengo como resultado aproximadamente 32 millones de bytes (256 millones de bits) de información. Con un clic de mi cámara produzco alrededor de 256 millones de ceros y unos. Si mi cámara está en modo video y filmo un video de cinco segundos de 24 fotogramas por segundo, consigo producir más de 30 billones de bits de información.
Probablemente ha escuchado el dicho: “Una imagen vale más que mil palabras.” Actualmente el texto de una novela de 250 páginas requiere menos de un millón de bytes de almacenamiento. Entonces se puede concluir que una fotografía a color ¡equivale a 32 libros!
Si estos números no lo abruman completamente, entonces considere el *Large Hadron Collider LHC (acelerador de partículas). En el momento en el que se ejecuta un experimento, el equipo toma alrededor de 40 millones de fotografías por segundo. Un segundo de información del acelerador es equivalente a 13 años de televisión en alta definición (HD) o varios cientos de millones de libros. ¡Esto es mucha información!
Datos, Información, Conocimiento, Sabiduría y Visión al Futuro
“Antes de quedar extasiado con gadgets (dispositivos) maravillosos y fascinantes pantallas de video, déjeme recordarle que la información no es conocimiento, el conocimiento no es sabiduría, y la sabiduría no es visión al futuro. Cada uno proviene del anterior y todos son necesarios.” (Arthur C. Clarke; Escritor británico de ciencia ficción, inventor y futurista; 1917-2008.)
El siguiente diagrama expande la aseveración de Clarke y presenta algunas definiciones.
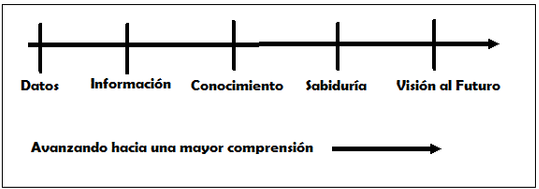
Datos: Datos y/o cifras sin procesar normalmente obtenidas a partir de instrumentos de medición.
Información: Datos que han sido procesados y estructurados, añadiendo contexto e incrementando su significado.
Conocimiento: Habilidad estratégica y práctica en el uso de la información para alcanzar objetivos específicos.
Sabiduría: Habilidad en la selección de objetivos consistentes con un conjunto de valores, tales como los valores humanos.
Visión al futuro: Habilidad en la predicción de resultados dados por las acciones y decisiones que fueron tomadas.
Usualmente las personas usan el término información para incluir las 5 categorías antes mencionadas: datos, información, conocimiento, sabiduría y visión al futuro. Dentro de cualquier disciplina de estudio podemos preguntarnos acerca de la credibilidad y validez de la información.
El ejemplo mencionado anteriormente de la cámara digital nos indica que ciertamente tenemos una sobrecarga de información, tenemos computadoras y otras máquinas automatizadas que procesan los datos. La fotografía que tomé con mi cámara puede ser impresa a color por 15 o 20 centavos (de dólar americano). Así puedo observar y apreciar la foto, compartirla con amigos, y guardarla en un álbum fotográfico. De esta manera estoy lidiando con una fotografía impresa, en vez de 32 millones de bytes de datos.
Un poco de Historia de la Computación
UNIVAC, la primera computadora electrónica-digital producida con fines comerciales, fue puesta a la venta en Junio de 1951. En ese entonces las computadoras eran consideradas aparatos para el procesamiento de datos. Gradualmente las computadoras fueron convirtiéndose en máquinas para el procesamiento de información. Al inicio de mis estudios de Ciencias Computacionales aprendí que “Una computadora es una máquina para la entrada (input), almacenamiento, procesamiento y salida (output) de información.” Con el tiempo la disciplina de Ciencias Computacionales fue re-nombrada Ciencias Computacionales y de Información.
El campo de las Ciencias Computacionales y de Información ha crecido substancialmente a medida que ha ido aumentado la capacidad de las computadoras. Podrá sorprenderle que la Asociación de Máquinas Computacionales (Association for Computing Machinery) celebró su 20ava conferencia anual sobre Knowledge and Data Mining (Conocimiento y Minería de Datos) el 27 de agosto del 2014. El éxito que tuvo la computadora IBM llamada Watson en el 2011, al jugar y vencer a los jugadores del programa de televisión Jeopardy, deja muy en claro que las computadoras se han vuelto poderosas máquinas procesadoras de conocimiento.
Actualmente pensamos en las computadoras como máquinas para el ingreso (input), almacenamiento, procesamiento, salida de información y conocimiento. La sabiduría y la visión al futuro aún deben estar a cargo del usuario. Los científicos en computación y en otras ciencias, continúan luchando con la naturaleza y el alcance de la inteligencia computacional actual y la idea de que, eventualmente, las computadoras podrán superar a los humanos en inteligencia.
Sobrecarga de Información
“Se recibe tanta información a lo largo del día que al final se pierde el sentido común” (Gertrude Stein; Escritora Estadounidense, poeta y feminista; 1874-1946.)
Recuerdo los “viejos tiempos” cuando mi esposa y yo compramos la Enciclopedia Británica. Parecía ser una inversión enorme en aquel entonces, incluso le construí su propio librero.
Ahora tenemos Wikipedia que es gratuita en la web. Citando a Wikipedia (Trate de no reírse, estoy citando a Wikipedia hablando de sí misma. ¿Será creíble y válida esta información?):
Wikipedia en inglés tiene por si misma más de 2.6 billones de palabras, cien veces más que la Enciclopedia Británica que es la siguiente enciclopedia más grande en el idioma inglés.
Rutinariamente uso Google para búsquedas en la Web. Citando a John Koetsier (1/11/2013):
Una búsqueda (de Google) comienza desde luego con rastreo e indexación, y Google menciona que la web tiene ahora 30 trillones de páginas únicas e individuales. Esto es un crecimiento impresionante de treinta veces en cinco años, ya que Google reportó en el 2008 que la web contaba solamente con un trillón de páginas.
Google informa que archiva la información de esas 30 trillones de páginas en su índice, el cual actualmente contiene 100 millones de gigabytes. Eso es alrededor de mil terabytes, así que se necesitarían más de tres millones de dispositivos USB de 32GB para almacenar todos estos datos.
Cuando realiza una búsqueda, Google trata de predecir no solo lo que se está escribiendo en la zona de diálogo, si no también de entender a lo que uno se refiere. Así que algoritmos de ortografía, auto-completar, sinónimos y comprensión de la consulta, comienzan a trabajar. Cuando Google cree que sabe lo que se desea, busca dentro de sus 30 trillones de páginas y 100 millones de gigabytes, pero no solamente muestra lo que encuentra.
Primero, un proceso de clasificación hace uso de más de 200 factores secretos muy bien guardados, para evaluar la actualidad del resultado, la calidad de la página, la edad del dominio, la seguridad y pertinencia del contenido, y contextos del usuario como localización, búsquedas pasadas, historia y conexiones en Google+ y muchas más.
Este último párrafo es particularmente importante. En esencia nos dice que Google filtra y elige los resultados de la búsqueda y nos presenta primeros en la lista a los que considera que nos serán más útiles. Google aprende acerca del usuario, y usa este conocimiento en el proceso de filtrado.
Subcarga de Información
Puede pensar que una búsqueda web le responderá a cualquier pregunta que se le pueda ocurrir y localizará cualquier información que desee encontrar. Pero ese no es el caso. Information underload (subcarga de información) es un término que describe la situación en la que no se logra encontrar la información deseada aunque se sabe que ésta existe. Pero ¿cómo se sabe que esta información existe?
En mi opinión, es mejor pensar en information underload en función de una combinación de:
No saber qué información existe. Cuando formulo una pregunta o presento un problema a la Web, sería excelente que la Web tuviera suficiente inteligencia para decirme si en ese preciso momento existe una respuesta a dicha pregunta o problema. El sistema de recuperación de información podría entonces explicar cuáles son las áreas de investigación y desarrollo prometedoras que están teniendo progreso en dicha área y suministrar acceso a esta información.
No ser capaz de recuperar ciertas partes de la información que se sabe existe. Gran parte del conocimiento que ha sido adquirido por la raza humana aún no está en línea y mucho de lo que se encuentra en línea sólo se puede ver después de un pago. Por otro lado, mucha información es de propiedad privada o “secreta.” Desearía que el sistema de recuperación de información me informara acerca de dichas situaciones y que me indicara la razón por la cual no estoy teniendo acceso a la información que quiero.
No tener el conocimiento y habilidades necesarias para hacer uso efectivo de la información que se me proporciona. Un buen sistema de recuperación de información debería saber mi historial educativo formal e informal, mis intereses y cualquier otra información que le ayudara a decidir y presentar información a un nivel que yo en lo particular pudiera entender. (Si solamente he terminado la preparatoria, no deseo obtener un resultado diseñado para ¡ser entendido por Doctorados en Biología!) En el futuro, un sistema de recuperación de información será incluso una máquina que enseña. Cuando estoy explorando cierto tema, el sistema me hará saber qué material educativo disponible puede ayudarme a aprender más acerca del tema.
Observaciones Finales
La acumulación total de información es enorme y está en constante crecimiento. Sufrimos de ambos males, la sobrecarga de información y la subcarga de Información. Navegadores de base amplia como Google no examinan el contenido de las páginas web basándose en la credibilidad y validez. Ciertamente no presentan ninguna advertencia como: Lectores, ¡Cuidado! Este navegador no asume responsabilidad por la precisión de los resultados presentados.
Aquí hay algunos puntos importantes que considerar:
1. Mientras buscamos información que necesitamos, encaramos el problema de: “Entra basura, sale basura” (Garbage in, garbage out) GIGO. Mucha información incorrecta o sesgada forma parte de la información total a la cual tenemos acceso. Incluso un experto en un tema específico puede tener problemas separando el trigo de la paja en su área. No nos sorprende que gente ordinaria sea fácilmente engañada por lo que lee en línea. A nuestro sistema educativo le falla el enseñar a los estudiantes a saber discernir y evaluar las fuentes de información con un enfoque de credibilidad y validez.
2. Se requiere educación y experiencia sustancial para lograr hacer uso efectivo de la información acumulada disponible. Resulta interesante contrastar la Web actual con una Web Inteligente del futuro que provea respuestas de acuerdo al conocimiento, experiencia y contexto específico de acuerdo a cada individuo que hace una búsqueda. Lo cierto es que falta recorrer un largo trayecto para lograr este nivel de individualización.
3. Piense en lo complicado que es el comunicarle a la computadora un problema o una pregunta para que solamente nos brinde los resultados útiles y valiosos. En lo personal, me siento bastante descontento al realizar una búsqueda y obtener miles o millones de resultados. Éste problema puede ser atacado de dos maneras diferentes: una es la de proporcionar a los estudiantes el conocimiento y práctica necesaria para lograr comunicarse efectivamente con una computadora, y refinar su comunicación si ésta no produce los resultados que necesitan. La segunda manera es la de crear sistemas de recuperación de información más inteligentes, lo cual se está logrando gradualmente gracias a la inteligencia artificial.
*Large Hadron Collider (LHS) es un gran acelerador de partículas localizado en el laboratorio CERN en la frontera de Francia y Suiza, cerca de Ginebra. La operación de este acelerador se inició en el 2008 y su propósito inicial era proveer evidencia de la existencia del Higgs boson. Más información en: http://gizmodo.com/5914548/the-large-hadron-collider-throws-away-more-data-than-it-stores
Referencias:
Koetsier, J. (3/1/2013). How Google searches 30 trillion web pages, 100 billion times a month. (Cómo Google busca en 30 trillones de páginas web, 100 billones de veces al mes.) VB News. Retrieved 11/1/2014 from http://venturebeat.com/2013/03/01/how-google-searches-30-trillion-web-pages-100-billion-times-a-month/.
Moursund, D. (2014). Information underload and overload. (Sobrecarga y subcarga de Información) IAE-pedia. Retrieved 11/1/2014 from http://iae-pedia.org/Information_Underload_and_Overload.
Acerca del Autor:
David Moursund obtuvo su doctorado en matemáticas en la Universidad de Wisconsin-Madison. Enseñó en la Universidad de Oregón en los departamentos de Matemáticas, Ciencias de la Computación, y Formación Docente. Fundó la Sociedad Internacional para Tecnología Educativa (International Society for Technology in Education- ISTE), y fue director ejecutivo de la misma por 19 años, estableciendo su publicación emblemática: Aprendizaje y Liderazgo con Tecnología (Learning and Leading with Technology) ahora llamada Entrsekt, son sólo algunos de los hechos destacados en su carrera. Fue profesor titular o co-titular de 82 estudiantes de doctorado. Es autor y co-autor de más de 60 libros académicos y cientos de artículos. Ha dictado cientos de conferencias profesionales y talleres.
En el 2007 fundó Information Age Education- IAE (Educación de la Edad de la Información), una empresa sin fines de lucro dedicada a mejorar la enseñanza y el aprendizaje de personas de todas las edades alrededor del mundo. Para más información visite: http://iae-pedia.org/